
How to Get Started with Predictive Maintenance
Predictive maintenance is a multi-step process of monitoring a specific set of variables for a machine or asset to determine its condition, forecast its future condition, and schedule maintenance in accordance with need instead of at model-based time intervals. The process involves:
- Monitoring equipment to collect data about its condition and performance
- Analyzing the data to convert it into actionable information
- Acting on the insights consistent with established policy
Unscheduled downtime can have a major effect on productivity and profitability. As a result, organizations increasingly seek to apply predictive maintenance techniques to monitor equipment health and prevent unscheduled downtime. Predictive maintenance provides a methodology for improving the lifetime and performance of assets. It helps avoid catastrophic failure and maximize asset utilization. Predictive maintenance makes it possible to strategically allocate maintenance hours to optimize the performance of equipment throughout the facility.
How to Build a Predictive Maintenance Program
Adding predictive maintenance to an organization’s activities is not as easy as it sounds. Common pitfalls can trap the unwary, costing time and money while failing to deliver results. Here, we will focus on the strategies and technology required for successful transition.
- Establish a Strategy
- Choose the right asset to test
- Develop a Pilot Program to Prove Success
- Set a response procedure
- Build a data strategy
- Scale to more assets
1. Establish a Strategy
Switching to predictive maintenance is a process, not an event. It involves hardware changes, software changes, and most of all, changes to the manufacturing and maintenance culture. Success starts with strategic planning.
Especially in complex manufacturing environments, attempting to apply predictive maintenance to all assets simultaneously is a quick route to failure. It frequently leads to a deluge of data that rarely even gets used, let alone provides insights. The result is often an expensive effort that squanders money and staff hours, causes frustration, and generally fails to deliver the promised benefits.
The best approach is to start small, with a focused pilot program. Choose a single issue to address. Be patientthe goal is to establish a robust process and log a success. Once the pilot project is complete, other low-hanging fruit will appear.
2. Choose the Right Asset to Test
Making a smooth transition to predictive maintenance depends on the success of the pilot program. That starts with choosing the right asset to monitor. There are several basic classes that lend themselves to predictive maintenance and fast results.
Assets with a history of failure
Assets that have failed previously, particularly if they have failed frequently, are excellent candidates for a pilot program. Applying monitoring and predictive maintenance techniques not only help prevent downtime, they generate data that could help identify root cause of failure. This opens the way to potentially modifying operations and mitigating the problem.
Critical assets
Traditionally, condition monitoring for predictive maintenance was applied to expensive equipment such as hydroelectric or gas turbines. Motors costing a few hundred dollars each were not considered important enough to justify purchasing and installing monitoring equipment. However, this equipment may still be critical; if a blower motor is essential to the operation of a production line that feeds the entire plant, then that motor is a critical asset, whether it costs $20 or $20,000.
Troubled assets
For operations running around the clock or on tight deadlines, shutting down the line for unscheduled maintenance can be an expensive proposition. Predictive maintenance equips maintenance and operations staff to carefully run the asset as long as possible with the assurance that if condition begins to change, they can stop the asset before catastrophic failure takes place.
Difficult to replace assets
Some assets require expensive equipment for the replacement process. A rooftop fan, for example, might require a hoist or crane that can be expensive to rent, time consuming to operate, and unavailable on short notice. Receiving advance warning of issues makes it possible to schedule maintenance and minimize interruption.
Difficult-to-source assets
In a perfect world, the storage room in the maintenance department would have a replacement part for every component on the floor. That simply isn’t possible, either logistically or financially, however. They may have long lead times, particularly if they require customization. Short turnarounds may entail expediting fees that will increase price by a substantial amount.
Remote and hard-to-reach assets
Assets that are difficult to access are good candidates for a predictive maintenance program. This may involve an asset in an inaccessible location such as a rooftop during wintertime or in a confined space or in a hazardous location. Overtaxed maintenance staff may avoid monitoring as a result. Hard-to-reach assets may also present a concern if the asset cannot be safely monitored while running.

Image: Often overlooked, cooling towers and fans are difficult to reach, remote, and may be difficult to replace. Depending on the process, they may also be critical to production making them good candidates to start a predictive maintenance program with.
3. Develop a Predictive Maintenance Pilot Program to Prove Success
Predictive maintenance uses a variety of technologies to monitor the condition of rotating equipment. Each technology operates over a different time window (see table). It’s important to match the timeframe to the needs of the application. Some methods allow you to detect problems years before the may equipment fail, but you should consider the amount of early notice needed to act.
Select the right condition monitoring method for the asset
| Technology (Time frame of Advanced Warning) | Pros | Cons | Best Used For |
| Ultrasonic Sensing (Leading Indicator, Years) | High-frequency monitoring to detect bearing issues far in advance | Will not detect low frequency and therefore not suitable for monitoring assets closer to failure. | Early bearing failure notice. Detecting proper bearing lubrication right after lubricant change |
| Oil Analysis (Leading Indicator, Years) | Very detailed information. Can determine source of wear but need to know composition of components. | Requires lab equipment (spectrometer). Can be expensive. Cannot see dynamic load issues (i.e. how changing loads are affecting wear). | Rotating equipment (bearings, gear boxes and motors) |
| Vibration monitoring (Leading Indicator, Months) | Very detailed information. Can determine root cause of vibration but need a baseline. Can troubleshoot dynamic loading issues. | Need training to interpret data. Traditionally not cost effective (changing with new IoT systems). | Rotating equipment (bearings, gear boxes and motors). Linear motion equipment (e.g. presses) |
| Current Sensing (Leading Indicator, Months) | Can be implemented at the drive end (away from rotating asset) | For detecting electronic issues with motor current only – not mechanical issues. | Motors only, not ideal for other bearings and gearboxes |
| Thermography (Lagging Indicator) | Easy to implement and interpret data | Not suitable for continuous monitoring. Does not provide warning of issues far in advance. Can’t identify root causes of issues | Rotating equipment (bearings, gear boxes and motors) |
| Audible Noise (Lagging Indicator) | Easy to implement and interpret data | Not suitable for continuous monitoring. Does not provide warning of issues far in advance. Can’t identify root causes of issues | Rotating equipment (bearings, gear boxes and motors) |
For most facilities, years of notice may be too far in advance to act. When considering a pilot program, where short term results are ideal, vibration analysis is arguably the most effective monitoring technology for rotating assets. One of the key benefits is that it lends itself to continuous monitoring by software. The vibration analyst establishes triggers and sets alerts for whenever a condition is violated.
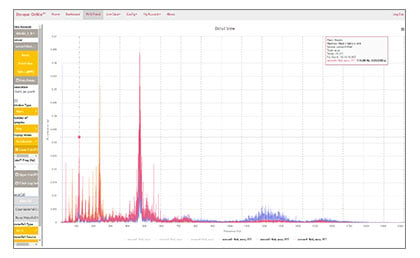
Graph: Vibration data can be used to predict several failure modes in rotating assets including misalignment, looseness, bearing defects and more.
Learn more about vibration analysis best practices and continuous vibration monitoring here
With the advent of the industrial internet of things (IoT), devices that utilizes cloud-storage and embedded computing have driven down the cost of continuous vibration monitoring to be accessible for any facility. Some of these devices allow multiple sensor inputs, such as temperature and speed, to provide a more complete picture of asset health.
Consider the data acquisition approach
The traditional approach to condition monitoring has been to take manual readings, almost always using a handheld device. This is generally performed on a scheduled basis as part of route-based monitoring. This is a useful technique but it has a major drawback: It can only reveal the status of the equipment at the time of the reading. If a fault develops immediately after, it will not be detected until the event of failure or the next reading, whichever happens first. As a result, this approach is not truly predictive.
For these reasons, organizations have increasingly been adopting continuous online condition monitoring technology. These systems use a sensor installed on the equipment for continuous readout of data. They can be interrogated on a schedule or networked in order to export data for analysis on a near-real-time basis. Built-in triggering and analytics functionality can enable them to send alerts in the event any parameters exceed preset thresholds.
4. Set a Response Procedure
The next step of a predictive maintenance plan is to establish a procedure for responding to anomalies. If the plan is based on continuous online condition monitoring, the procedure is as simple as awaiting instructions from the vibration tech or field technician. Based on their analysis, they will most likely give one of three directions:
- Shut down immediately.
- Run for a limited time if required to meet production goal.
- Run indefinitely and keep monitoring until regularly scheduled downtime. In this case, parameters should be set regarding any behavior that would call for immediate shutdown of the machine.
Once the detailed plan is in place, it is time for the fun part: installing the sensor, acquiring data, and gaining a better understanding of the assets. Be sure to document the project and record successes. Conduct a postmortem to review lessons learned. They will be helpful in the next phase when predictive maintenance is extended to additional assets.
5. Build a Data Analysis Strategy
Before scaling to multiple assets, a data analysis strategy should be established. This is particularly important for continuous online monitoring. The data volumes are large enough that they can consume significant amounts of storage space and bandwidth.
To simplify, there are two options: in-house or third-party service providers (field technicians) or analysis by in-house experts. If the responsibility will remain in-house, organizations need to determine whether that will be performed by an existing expert, whether staff will need to be trained, or whether an expert with the required skills will be hired. It is important to remember that vibration monitoring requires care and attention. Expecting existing staff to acquire the necessary expertise to take on the task, particularly while maintaining pre-existing duties, may be unrealistic.
For companies with limited resources, the easiest route may be to work with a third-party field technician. These individuals and organizations have expertise in reliability and condition monitoring. With the aid of an online condition monitoring sensor that enables them to access data remotely, they can very effectively track asset health and troubleshoot any problems.
6. Scale Predictive Maintenance to More Assets
Once you have proven the success of the pilot program and identified the resources needed to monitor data, return to the list of assets identified as candidates for the pilot program. These may include critical, troubled, difficult to source or difficult to replace assets as well as assets in remote locations and those that have a history of failure. While it is ideal to develop predictive maintenance programs for all assets above, consider the cost of downtime and the potential return on investment for each asset and prioritize from there.
Additional Resources:
Learn more about vibration analysis best practices and continuous vibration monitoring here
Learn how to choose the best vibration sensors for rotating equipment
Learn how to evaluate cloud-based condition monitoring security
{{#if customLayout}}
{{html customLayout}}
{{else}}
{{#each items}}
{{#if products.results.length}}
{{products.title}}
{{/if}}
{{#if (or categories.results.length content.results.length queries.results.length)}}
{{#each products.results}}
{{/each}}
{{#if queries.results.length}}
{{queries.title}}
{{/if}}
-
{{#each queries.results}}
- {{query}} {{/each}}
-
{{#each productSuggestedQueries.results}}
- {{query}} {{/each}}
-
{{#each contentSuggestedQueries.results}}
- {{query}} {{/each}}
-
{{#each categories.results}}
- {{html title}} {{/each}}
-
{{#each content.results}}
- {{html title}} {{/each}}
{{#if (eq title "Search within results")}}
Search Within Results
{{#if tooltip}}
{{else}}
{{title}}
{{#if tooltip}}
{{/if}}
{{#unless collapsed}}
{{#if searchable}}
{{/if}}
{{#if (eq type "checkbox")}}
{{/unless}}
{{#if (myEq attributes.type "Product")}}
{{#if (myEq attributes.is_family "No")}}

{{#if attributes.list_price}} {{#if attributes.leadtime}} Buy Now!
{{/if}} {{/if}} View Product Info
{{else}}

{{#if attributes.family_page_link}} View Series Info {{else}} More Info {{/if}}
{{/if}}
{{else if (myEq attributes.type "Content")}}
{{#if (myEq attributes.content_type "Page")}}
More Info
{{else if (myEq attributes.content_type "BlogPost")}}
More Info
{{else}}
UNKNOWN TYPE 2 (type:{{attributes.type}}, content_type:{{attributes.content_type}})
{{/if}}
{{else}}
UNKNOWN TYPE 1: (type:{{attributes.type}}, content_type:{{attributes.content_type}})
{{/if}}
{{#if attributes.family_id}}
{{attributes.family_id}}
{{/if}}
{{#if attributes.part_number}}
{{/if}}
{{#if (myEq attributes.consult_factory_price "1")}}
Consult Factory
{{else}}
{{#if (isNumber attributes.list_price)}}
{{currency attributes.list_price}} {{attributes.currency_code}}
{{/if}}
{{/if}}
{{attributes.description}}
{{#if (myEq attributes.consult_factory_leadtime "1")}}
Consult Factory
{{else}}
{{#if (isNumber attributes.leadtime)}}
{{isInt attributes.leadtime}} {{attributes.leadtime_period}}
{{/if}}
{{/if}}
{{#if attributes.data_sheet_link}}
Download Datasheet
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
{{#if attributes.list_price}} {{#if attributes.leadtime}} Buy Now!
{{/if}} {{/if}} View Product Info
{{#if attributes.family_id}}
{{attributes.family_id}}
{{else}}
{{/if}}
{{#if attributes.description}}
{{#if attributes.family_page_link}}
{{truncateWithMore attributes.description attributes.family_page_link}}
{{else}}
{{truncateWithMore attributes.description attributes.url_detail}}
{{/if}}
{{/if}}
{{#if attributes.data_sheet_link}}
Download Datasheet
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
{{#if attributes.family_page_link}} View Series Info {{else}} More Info {{/if}}
{{#if attributes.description}}
{{#if attributes.family_page_link}}
{{truncateWithMore attributes.description attributes.family_page_link}}
{{else}}
{{truncateWithMore attributes.description attributes.url_detail}}
{{/if}}
{{else if attributes.description_short}}
{{#if attributes.family_page_link}}
{{truncateWithMore attributes.description_short attributes.family_page_link}}
{{else}}
{{truncateWithMore attributes.description_short attributes.url_detail}}
{{/if}}
{{/if}}
{{#if attributes.data_sheet_link}}
Download Datasheet
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
More Info
{{#if attributes.description}}
{{#if attributes.family_page_link}}
{{truncateWithMore attributes.description attributes.family_page_link}}
{{else}}
{{truncateWithMore attributes.description attributes.url_detail}}
{{/if}}
{{else if attributes.description_short}}
{{#if attributes.family_page_link}}
{{truncateWithMore attributes.description_short attributes.family_page_link}}
{{else}}
{{truncateWithMore attributes.description_short attributes.url_detail}}
{{/if}}
{{/if}}
{{#if attributes.data_sheet_link}}
Download Datasheet
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
{{/if}} {{#if attributes.installation_manual_link}} Download Installation Manual {{/if}}
More Info
{{#if strings.summary}}
{{strings.summary}}
{{/if}}
{{#if content.customHtml}}
{{html content.customHtml}}
{{/if}}
{{#if (myEq content.heading "Incremental Encoders")}}
 {{else if (myEq content.heading "Absolute Encoders")}}
{{else if (myEq content.heading "Absolute Encoders")}}
 {{/if}}
{{/if}}
{{else if (myEq content.heading "Absolute Encoders")}}
{{/if}}
{{searchResultsFor}}